Application deployment automation solutions are key when hosting an application in the cloud. The combination of release automation and the IaaS resources abstraction layer allows you to easily migrate your application to any common cloud provider.
Automation shouldn’t be adopted solely in order to move to the cloud. It has many benefits above and beyond this need. Increasingly popular movements such as Agile Application Lifecycle Management (ALM) and DevOps fully support automation as a method to achieve continuous delivery. Organizations today have to keep up with a high rate of releases in complex environments. Automating application deployments and infrastructure provisioning is what makes it possible. Some IT professionals even take DevOps a step further than NoOps.
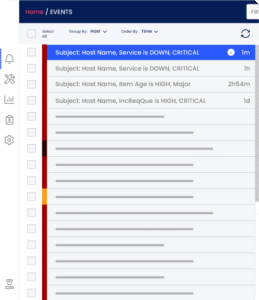
However, automating cloud processes also creates the need for increased monitoring and alerts. Automation development should be considered carefully as it adds more complexity to the process and its R&D investments. The final solution must take into consideration the need for monitoring and auditing each of the automatic processes in order to find bottlenecks and bugs. Automation without monitoring generates a great risk to the business.
 Monitoring automation reduces the need for on-line engineers and fast response, however, it is crucial to remember that automation is basically scripts and code that should be treated as another application and needs to be constantly developed, tested, and maintained. This requires an experienced and qualified engineer/developer/integrator to constantly develop and maintain automation processes. When releasing new applications and updates, reviewing the automation programming should be a mandatory step in the application lifecycle. Since automation should be treated as an application it requires human monitoring to ensure that it works as expected.
Monitoring automation reduces the need for on-line engineers and fast response, however, it is crucial to remember that automation is basically scripts and code that should be treated as another application and needs to be constantly developed, tested, and maintained. This requires an experienced and qualified engineer/developer/integrator to constantly develop and maintain automation processes. When releasing new applications and updates, reviewing the automation programming should be a mandatory step in the application lifecycle. Since automation should be treated as an application it requires human monitoring to ensure that it works as expected.
We can look at the QA arena for comparison; in QA processes everyone is talking about automation but research shows only 10-15% of software tests are automated, the reasons for that are similar to the ones described above.
For example, let’s take a look at the AWS platform. Let’s assume an application running on AWS instance can work properly with up to 80% CPU and 200 requests per second. If there are delays in the network or a bug in the application, the queue in the application will start growing. The automation script will start adding more instances which, in the end of the process, will result in many instances launched unnecessarily wasting money. Furthermore, the problem will not be solved and nobody will be aware of it. Of course, there is always the possibility to add a script that will limit the number of instances launched but this script will also need to be monitored.
Currently, automation is predominately scripts that perform actions as a result of an event. In order to have sufficient automation, you must add “intelligent” scripts that can learn the system, and such automation does not exist or is very expensive to implement. Best practice suggests implementing a combination of automation and human intelligence (e.g. a monitoring engineer to monitor the application and automation).